손실함수(loss function)는 신경망(또는 다른 머신러닝 모델)에서 모델의 예측값과 실제 값 간의 차이를 측정하는 함수이다. 이 함수는 모델이 얼마나 잘 수행하고 있는지를 정량적으로 평가하기 위해 사용된다. 모델의 출력이 실제 값과 얼마나 가까운지를 평가하여, 모델의 파라미터를 업데이트하고 최적화하는 과정에서 중요한 역할을 한다.
손실함수의 역할
신경망에서 학습이 이루어지는 과정은 다음과 같다.
- 예측(Prediction): 신경망은 주어진 입력 데이터를 바탕으로 예측값을 생성한다.
- 손실 계산(Calculate Loss): 손실함수는 예측값과 실제 값(타겟) 간의 차이를 계산한다. 이 값이 클수록 모델의 예측이 부정확한 것이다.
- 역전파(Backpropagation): 손실함수의 값을 최소화하기 위해 역전파 알고리즘이 사용다. 이 과정에서 손실함수의 값에 따라 신경망의 가중치가 업데이트된다.
- 최적화(Optimization): 최적화 알고리즘(예: SGD, Adam 등)은 손실함수를 최소화하도록 가중치를 조정하여 모델의 성능을 향상시킨다.
주요 손실함수 종류
손실함수는 문제의 유형에 따라 다르다. 대표적인 손실함수는 다음과 같다.
1. 평균 제곱 오차(MSE, Mean Squared Error):
회귀 문제에서 많이 사용된다.
예측값과 실제 값 간의 차이를 제곱한 후 평균을 계산한다.

여기서 yi는 실제 값, y^i는 예측값, n은 데이터 포인트의 수이다.
2. 교차 엔트로피 손실(Cross-Entropy Loss):
분류 문제에서 많이 사용된다.
예측 확률과 실제 클래스 간의 차이를 측정한다.
이진 분류의 경우 Binary Cross-Entropy, 다중 클래스 분류의 경우 Categorical Cross-Entropy가 사용된다.
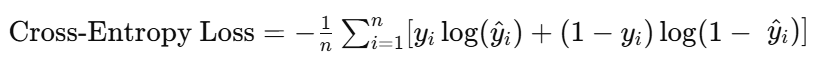

Cross-Entropy 그래프가 예측 확률과 실제 클래스 간의 차이가 클수록 갑이
3. 힌지 손실(Hinge Loss):
서포트 벡터 머신(SVM)과 같은 이진 분류 문제에서 사용된다.
예측값이 실제 클래스와 얼마나 멀리 떨어져 있는지를 측정한다.

4. 후버 손실(Huber Loss):
MSE와 MAE(Mean Absolute Error)를 혼합한 형태로, 회귀 문제에서 많이 사용된다.
큰 오차에 대해선 MSE처럼 작동하고, 작은 오차에 대해선 MAE처럼 작동한다.

여기서 a는 실제 값과 예측값의 차이이다.
손실함수는 신경망 학습의 핵심 요소로, 모델이 예측한 값이 얼마나 정확한지를 평가하고, 이를 바탕으로 모델의 파라미터를 조정하여 성능을 향상시키는 데 중요한 역할을 한다. 손실함수의 선택은 문제의 유형과 데이터의 특성에 따라 달라지며, 적절한 손실함수를 선택하는 것이 모델의 성능에 큰 영향을 미칠 수 있다.
'컴퓨터공학 > NN' 카테고리의 다른 글
| 경사하강법(Gradient Descent) (0) | 2024.08.28 |
|---|---|
| 신경망에서 사용되는 활성화함수들 (0) | 2024.08.28 |
| Word2Vec (0) | 2024.08.21 |
| 해석 가능한 인공지능(Explainable AI, XAI) (0) | 2024.08.20 |
| Forward-Forward Algorithm (0) | 2024.08.16 |